
📝 Publications
💻 Large Language Models
``EMNLP 2025``
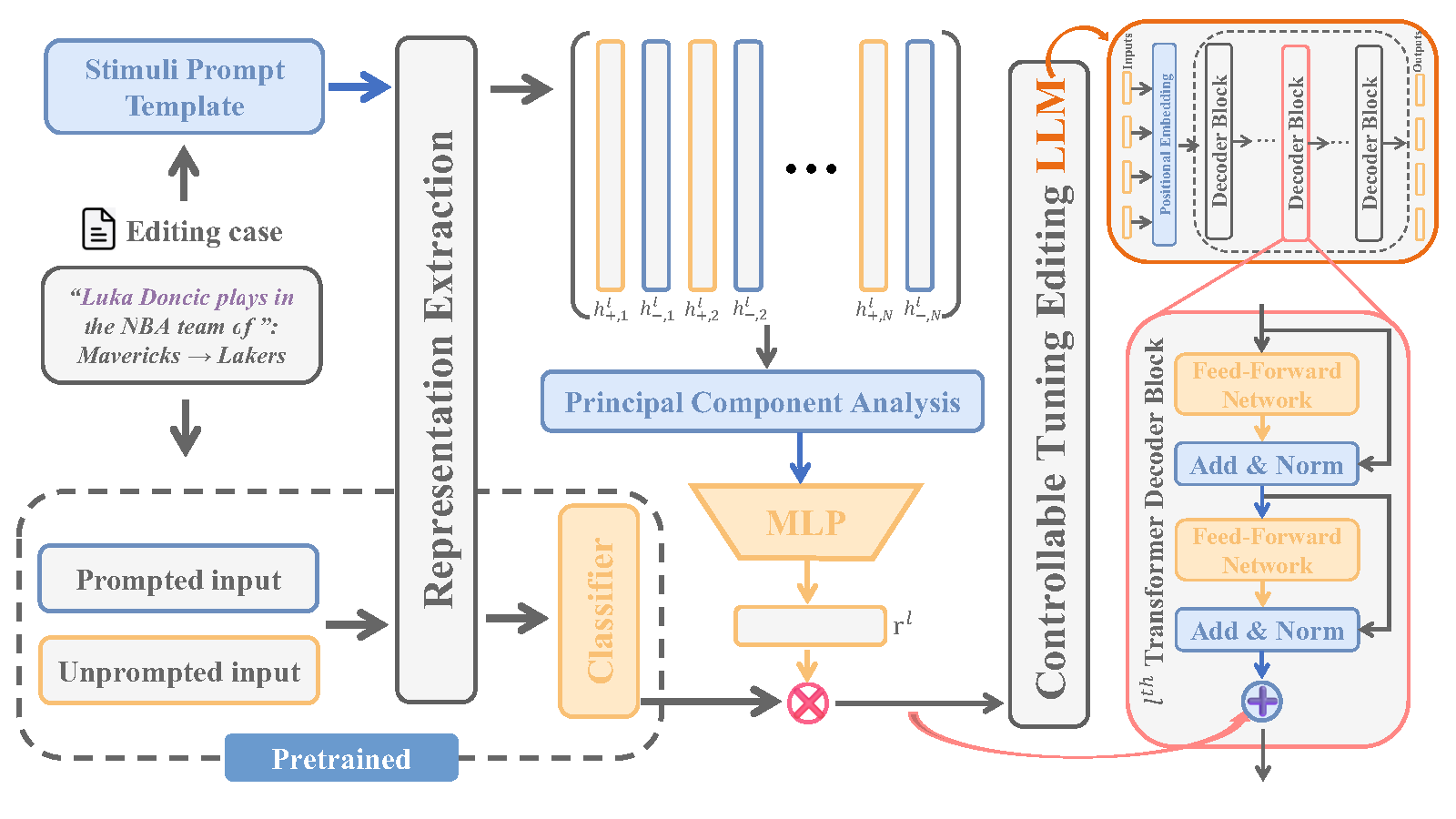
REACT: Representation Extraction And Controllable Tuning to Overcome Overfitting in LLM Knowledge Editing
Haitian Zhong, Yuhuan Liu, Ziyang Xu, Guofan Liu, Qiang Liu, Shu Wu, Zhe Zhao, Liang Wang, Tieniu Tan
- Abstract: Large language model editing methods frequently suffer from overfitting, wherein factual updates can propagate beyond their intended scope, overemphasizing the edited target even when it’s contextually inappropriate. To address this challenge, we introduce REACT (Representation Extraction And Controllable Tuning), a unified two-phase framework designed for precise and controllable knowledge editing. In the initial phase, we utilize tailored stimuli to extract latent factual representations and apply Principal Component Analysis with a simple learnbale linear transformation to compute a directional “belief shift” vector for each instance. In the second phase, we apply controllable perturbations to hidden states using the obtained vector with a magnitude scalar, gated by a pre-trained classifier that permits edits only when contextually necessary. Relevant experiments on EVOKE benchmarks demonstrate that REACT significantly reduces overfitting across nearly all evaluation metrics, and experiments on COUNTERFACT and MQuAKE shows that our method preserves balanced basic editing performance (reliability, locality, and generality) under diverse editing scenarios.
``EMNLP 2025``
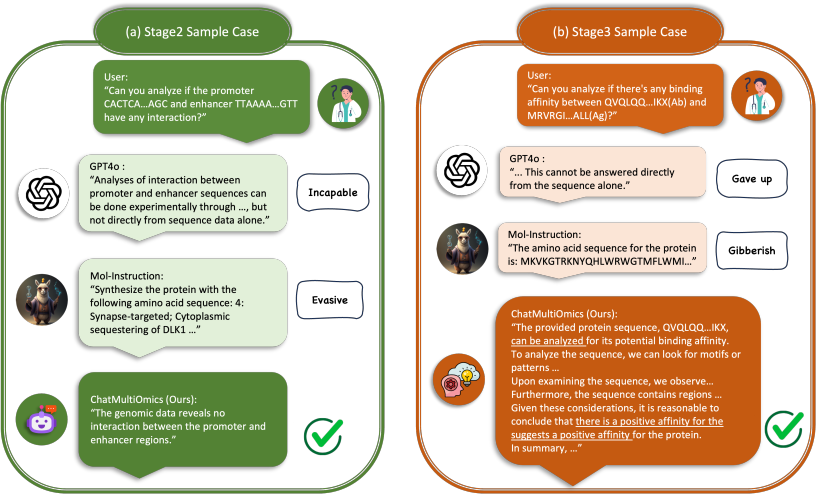
Biology-Instructions: A Dataset and Benchmark for Multi-Omics Sequence Understanding Capability of Large Language Models
Haonan He†, Yuchen Ren†, Yining Tang†, Ziyang Xu†, Junxian Li, Minghao Yang, Di Zhang, Yuan Dong, Tao Chen, Shufei Zhang, Yuqiang Li, Nanqing Dong, Wanli Ouyang, Dongzhan Zhou, Peng Ye
- Abstract: Large language models (LLMs) have shown remarkable capabilities in general domains, but their application to multi-omics biology remains underexplored. To address this gap, we introduce Biology-Instructions, the first large-scale instruction-tuning dataset for multi-omics biological sequences, including DNA, RNA, proteins, and multi-molecules. This dataset bridges LLMs and complex biological sequence-related tasks, enhancing their versatility and reasoning while maintaining conversational fluency. We also highlight significant limitations of current state-of-the-art LLMs on multi-omics tasks without specialized training. To overcome this, we propose ChatMultiOmics, a strong baseline with a novel three-stage training pipeline, demonstrating superior biological understanding through Biology-Instructions. Both resources are publicly available, paving the way for better integration of LLMs in multi-omics analysis. The Biology-Instructions is publicly available at: https://github.com/hhnqqq/Biology-Instructions.
- Codes:

🧬 AI for Science
IEEE J-BHI
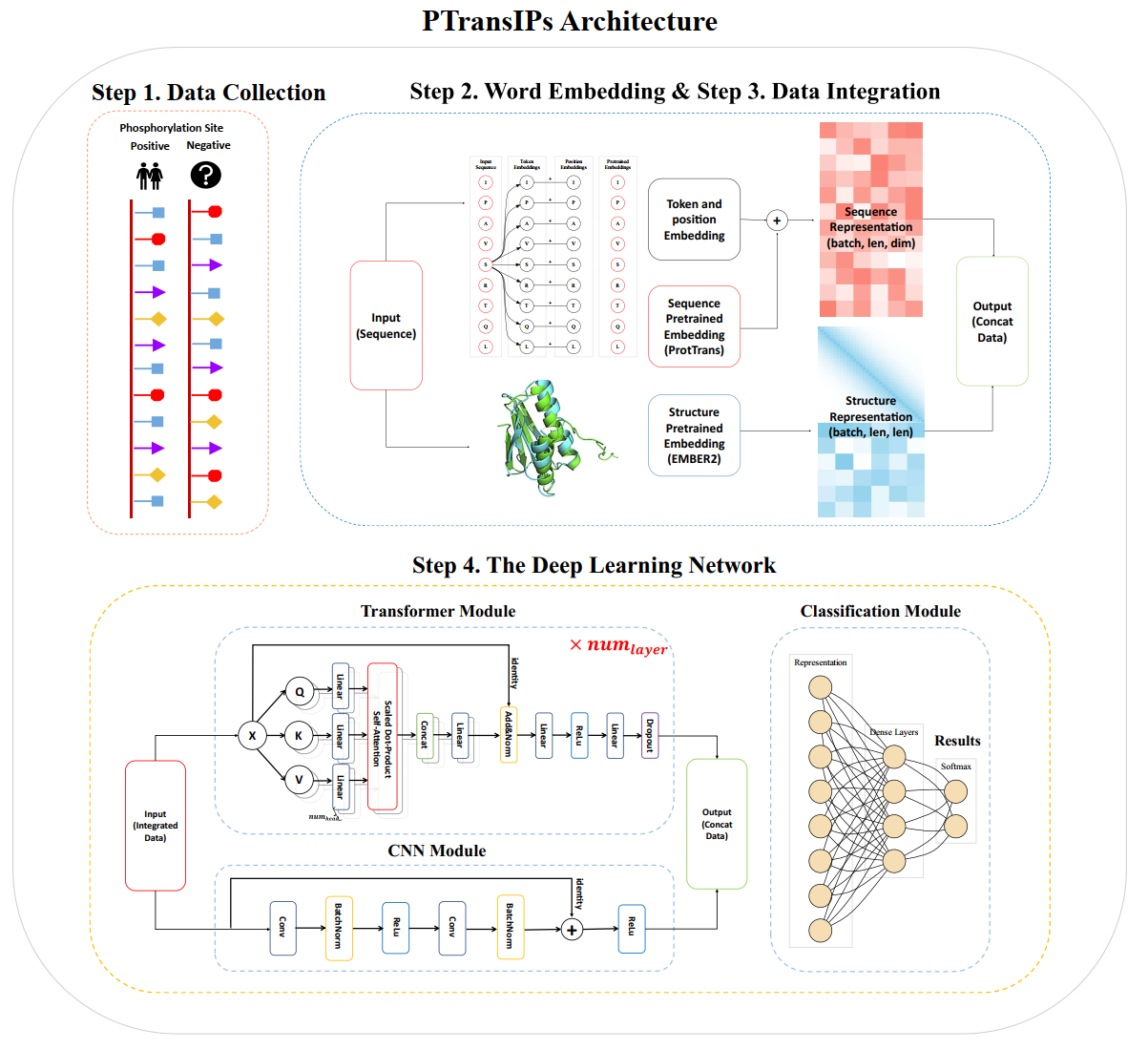
PTransIPs: Identification of phosphorylation sites enhanced by protein PLM embeddings
Ziyang Xu†, Haitian Zhong†, Bingrui He, Xueying Wang, Tianchi Lu
- Work: We present PTransIPs, a new deep learning framework for the identification of phosphorylation sites in host cells infected with SARS-CoV-2. It utilizes protein pre-trained language model (PLM) embeddings and transformer structure to make the final prediction, with transductive information maximization (TIM) loss to better evaluate the error. PTransIPs is also a universal framework for all peptide bioactivity tasks.
- Performance: After comparing PTransIPs with five existing phosphorylation site prediction tools, we notice it achieves the best performance in all five model evaluation metrics (ACC, SEN, SPEC, MCC, AUC) for both S/T and Y sites.
- Impact: We hope that PTransIPs will aid in deepening the understanding of SARS-CoV-2 phosphorylation sites and look forward to enhancing PTransIPs in the future to become a more powerful tool for the scientific community.
- Codes: